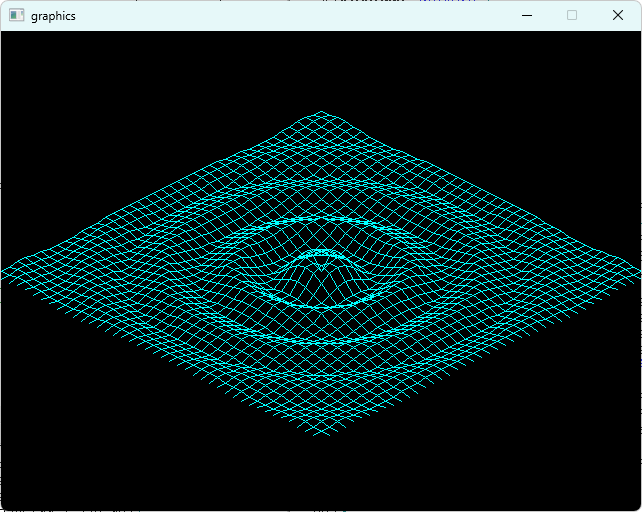
バイナリサイズ比較
(1) これをコンパイルして(リンクはしないで).textのサイズを調べる。
//#include "kharc.h"
int openWin(int xsiz, int ysiz);
int isClose(int win);
void wait(int msec);
void fillRect(int w, int xsiz, int ysiz, int x, int y, int col);
void drawLine(int w, int x0, int y0, int x1, int y1, int col);
int ff16Sqrt(int x);
int ff16Sin(int x);
void wave()
{
int w, t, x, y, d, z, x1, y1, gx[1764], gy[1764];
w = openWin(640, 480);
for (t = 0; isClose(w) == 0; t++) {
wait(8); fillRect(w, 640, 480, 0, 0, 0x000000);
for (y1 = 0; y1 < 42; y1++) { y = y1 - 20;
for (x1 = 0; x1 < 42; x1++) { x = x1 - 20;
d = ff16Sqrt((x * x + y * y) * 65536);
z = ff16Sin(((d * 652) >> 12) - 1043 * t) * 100 / (d + 327680);
d = y1 * 42 + x1;
gx[d] = (x * 8 - y * 8 + z * 0) + 320;
gy[d] = (x * 4 + y * 4 + z * 1) + 240;
if (x1 >= 1 && y1 >= 1) {
drawLine(w, gx[d - 43], gy[d - 43], gx[d - 42], gy[d - 42], 0x00ffff);
drawLine(w, gx[d - 43], gy[d - 43], gx[d - 1], gy[d - 1], 0x00ffff);
}
}
}
}
}
- このプログラムではintは32bit以上のビット幅を想定しています。
(2) 実験手順
>gcc --version
gcc (GCC) 3.4.5 (mingw-vista special r3)
Copyright (C) 2004 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
>gcc -c -Os 3dwave-bench.c
>objdump -h 3dwave-bench.o
3dwave-bench.o: file format pe-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 000001e4 00000000 00000000 0000008c 2**2
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 00000000 00000000 00000000 2**2
ALLOC, LOAD, DATA
2 .bss 00000000 00000000 00000000 00000000 2**2
ALLOC
- この場合、.textのサイズは0x1e4バイト。つまり484バイト。
- 実行ファイルは.textの情報だけからでは構築できないけれども、しかし大雑把には目安になると考えました。
- ELFでもCOFFでも(=つまりオブジェクトファイルフォーマットが違っても)、.textの中身は基本的には同じになりますし、サイズも同じになります。
(3) 結果のまとめ
| 107バイト | uck [ultra compact kharc: 超高密度の自作バイトコード] | (uckのみ、.textだけではなく全セクションを含んだ実行ファイルサイズ) | 2025.07.28版 |
| | | |
| 276バイト | arc-elf (HS) | -g -Os -fno-builtin -fomit-frame-pointer -fno-inline | GNU C17 (GCC) version 11.5.0 (arc-elf) |
| 286バイト | thumb2-eabi | -mthumb -mthumb-interwork -march=armv7-a -g -Os -fno-builtin -fomit-frame-pointer -fno-inline | GNU C17 (GCC) version 11.5.0 (arm-eabi) |
| 307バイト | WCOFF x86 | アセンブラ手書き →(4)参照 | (考察)手書きすれば 20% くらい削減できるというめやすを得た。 |
| 320バイト | bfin-elf | -g -Os -fno-builtin -fomit-frame-pointer -fno-inline | GNU C17 (GCC) version 11.5.0 (bfin-elf) |
| 356バイト | ELF 32-bit LSB relocatable, ARM, EABI5 version 1 (SYSV) (たぶんThumb) | arm-linux-gnueabihf-gcc -c -Os -o a.o bench.c | arm-linux-gnueabihf-gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 |
| 383バイト | i386-elf | -Os | GNU C17 (GCC) version 11.5.0 |
| 404バイト | arm-eabi (armv4t) | -mcpu=arm7tdmi -marm -march=armv4t -g -Os -fno-builtin -fomit-frame-pointer -fno-inline | GNU C17 (GCC) version 11.5.0 (arm-eabi) |
| 436バイト | aarch64-elf (armv8-a+crc) | -mcmodel=large -mlittle-endian -mabi=lp64 -g -Os -fno-builtin -fomit-frame-pointer -fno-inline | GNU C17 (GCC) version 11.5.0 (aarch64-elf) |
| 484バイト | pe-i386 | gcc -c -Os 3dwave-bench.c | gcc (GCC) 3.4.5 (mingw-vista special r3) |
| 527バイト | ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV) | gcc -m64 -c -Os bench.c | gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 |
| 540バイト | ELF 64-bit LSB relocatable, ARM aarch64, version 1 (SYSV) | aarch64-linux-gnu-gcc -c -Os -o a.o bench.c | aarch64-linux-gnu-gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 |
| 601バイト | ELF 32-bit LSB relocatable, Intel 80386, version 1 (SYSV) | gcc -m32 -c -Os bench.c | gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 |
| 692バイト | alpha-linux (ev4) | -g -Os -fno-builtin -fomit-frame-pointer -fno-inline | GNU C17 (GCC) version 11.5.0 (alpha-linux) |
- kozosの坂井さんのおかげで、この表は40種類以上のCPUアーキテクチャについて記載できそうです。
(4) gccを使わずに、x86アセンブラ手書きで(1)のコードを作ってみた
- →307バイト
[FORMAT "WCOFF"]
[INSTRSET "i486p"]
[OPTIMIZE 1]
[OPTION 1]
[BITS 32]
[FILE '3dwave2.nas']
GLOBAL _wave
EXTERN __chkstk
EXTERN _openWin
EXTERN _isClose
EXTERN _wait
EXTERN _fillRect
EXTERN _ff16Sqrt
EXTERN _ff16Sin
EXTERN _drawLine
; t:[ebp-4], x:[ebp-8], y:[ebp-12], w:[ebp-16], x1:esi, y1:edi
[SECTION .text]
_wave:
pushad
mov ebp,esp
mov eax,16+1764*4*2
call __chkstk
push 480
push 640
call _openWin
pop ecx
pop ecx
mov dword [ebp-16],eax ; w
xor eax,eax
mov dword [ebp-4],eax ; t
lp0:
push 8
call _wait
xor eax,eax
push eax
push eax
push eax
push 480
push 640
push dword [ebp-16] ; w
call _fillRect
add esp,28
xor edi,edi
lp1:
lea eax,[edi-20]
mov dword [ebp-12],eax ; y
xor esi,esi
lp2:
lea eax,[esi-20]
mov dword [ebp-8],eax ; x
mov ecx,eax ; x
mov edx,dword [ebp-12] ; y
imul eax,edi,42
add eax,esi
lea ebx,[esp+eax*8]
lea eax,[ecx+40]
sub eax,edx
shl eax,3
mov dword [ebx+0],eax ; gx[d]=(x-y+40)*8
lea eax,[ecx+edx+60]
shl eax,2
mov dword [ebx+4],eax ; gy[d]=(x+y+60)*4
imul ecx,ecx
imul edx,edx
add ecx,edx
shl ecx,16
push ecx
call _ff16Sqrt
pop edx
push eax ; d
imul eax,eax,652
shr eax,12
mov ecx,dword [ebp-4] ; t
imul ecx,ecx,1043
sub eax,ecx
push eax
call _ff16Sin
pop ecx
imul eax,eax,100
cdq
pop ecx ; d
add ecx,327680
idiv ecx
add dword [ebx+4],eax
lea eax,[esi-1]
lea ecx,[edi-1]
or eax,ecx
js skp0
push 0xffff
push dword [ebx-42*8+4]
push dword [ebx-42*8+0]
push dword [ebx-43*8+4]
push dword [ebx-43*8+0]
push dword [ebp-16]
call _drawLine
push 0xffff
push dword [ebx-1*8+4]
push dword [ebx-1*8+0]
push dword [ebx-43*8+4]
push dword [ebx-43*8+0]
push dword [ebp-16]
call _drawLine
add esp,48
skp0:
inc esi
cmp esi,42
jl lp2
inc edi
cmp edi,42
jl lp1
inc dword [ebp-4]
push dword [ebp-16]
call _isClose
pop ecx
test eax,eax
jz lp0
mov esp,ebp
popad
ret
; >nask bench.nas bench.obj bench.lst
- (考察)手書きによって 383→307 になったので、手書きすれば 20% くらい削減できるというめやすを得た。
![[PukiWiki]](image/pukiwiki.png "[PukiWiki]")