Raspberry Piに関する話題 #02
(0) もくじ
(1) 日記形式
2024.05.04(土) #1
- ここ数日は、acl1ライブラリのX11/Arch64版を整備中・・・。これができれば、今まで作ってきたプログラムがRasPiZero2Wでも動くようになるはず!
2024.05.06(月) #1
- ビデオキャプチャーの反応が遅くて(OBSの反応が遅くて)、マウス操作がやりにくいなあと感じていたのですが、設定でFPSを10くらいに下げたら、反応が速くなりました!そっかー、ノートPCのマシンパワー不足で追いついていなかったのかー。
2024.05.09(木) #1
2024.05.09(木) #2
- Windows用に作っていたacl1ライブラリをLinux/X11でも使えるように移植しました。とはいえごく一部の機能だけですが。おかげで、kcube.cが動くようになりました。
#include <acl1.c>
void aMain(AComArg *aCA)
{
static int sqr[24] = { 7,6,2,3, 6,4,0,2, 1,0,4,5, 7,3,1,5, 3,2,0,1, 7,5,4,6 };
int sx[8], sy[8], b0[160], b1[160], y0, y1, x, y, c, dx, *b, yk, i, j, k, l, m;
AVec3 vert[8], v[8], th; double centerz[7], t;
for (i = 0; i < 8; i++) {
vert[i] = AVec3_mul(100, AVec3_new((i >> 2) - 0.5, ((i >> 1) & 1) - 0.5, (i & 1) - 0.5));
}
AWin *w = aOpenWin(256, 160, "kcube");
for (th = AVec3_new(0, 0, 0); AWin_isClose(w) == 0; ) {
th = AVec3_add(th, AVec3_mul(3.14159265358979323 / 180, AVec3_new(1.0, 1.5, 2.0)));
AMat33 mat = AMat33_mul(AMat33_rotZ(th.z), AMat33_mul(AMat33_rotY(th.y), AMat33_rotX(th.x)));
for (i = 0; i < 8; i++) {
v[i] = AMat33Vec3_mul(mat, vert[i]);
t = 300.0 / (v[i].z + 400);
sx[i] = (AInt) (v[i].x * t) + 128;
sy[i] = (AInt) (v[i].y * t) + 80;
}
for (l = 0; l < 6 * 4; l += 4) {
centerz[l / 4] = v[sqr[l]].z + v[sqr[l+1]].z + v[sqr[l+2]].z + v[sqr[l+3]].z + 1e6;
}
aWait(50);
aFillRect(w, 160, 160, 48, 0, 0x000000);
for (centerz[6] = 0; (i = aArgMaxLstDbl(centerz, 0, 7)) < 6; ) {
y0 = 999; y1 = 0; c = AWin_col16(i + 1);
centerz[i] = 0; i = i * 4;
for (l = 0; l < 4; l++) {
b = b0; j = sqr[i + l]; k = sqr[i + (l + 1) % 4];
AUpdateMinMax(y0, y1, sy[j]);
if (sy[j] == sy[k]) continue;
if (sy[j] > sy[k]) { b = b1; ASwapTmp(j, k, m); }
yk = sy[k]; dx = (sx[k] - sx[j]) * 65536 / (yk - sy[j]);
x = sx[j] * 65536 + 32768;
for (y = sy[j]; y <= yk; y++) {
b[y] = x >> 16;
x += dx;
}
}
for (y = y0; y <= y1; y++) {
aFillRect(w, b1[y] - b0[y] + 1, 1, b0[y], y, c);
}
}
}
}
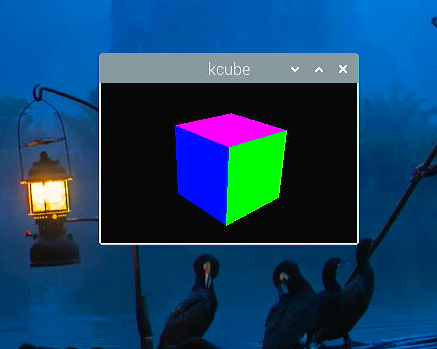
- この画像だと回っている感じがあまりないですが、もちろん回っています。
- 簡単ではありますが、こんなレイトレーシングもできました。
#include <acl1.c>
AClass(Isect) { AVec3 hitPoint, nor, col; double distance; };
AClass(Object) { AVec3 pos, col, nor; double rad; /* radius */ }; // Sphere(pos, col, rad) or Plane(pos, col, nor).
AClass(Util) { AVec3 light; Object s1, s2, s3, p; };
AInt32 col256(double t) { return (AInt32) (255.99999 * aSaturateDbl(t, 0.0, 1.0)); }
void Sphere_intersect(Object s, AVec3 rayOrigin, AVec3 rayDir, AVec3 light, Isect *i)
{
AVec3 rs = AVec3_sub(rayOrigin, s.pos);
double b = AVec3_dot(rs, rayDir), c = AVec3_dot(rs, rs) - s.rad * s.rad, d = b * b - c;
if (d < 0.0) return;
double t = - b - sqrt(d);
if (t < 1.0e-4 || t > i->distance) return;
i->hitPoint = AVec3_add(rayOrigin, AVec3_mul(t, rayDir)); i->distance = t;
i->nor = AVec3_normalize(AVec3_sub(i->hitPoint, s.pos));
i->col = AVec3_mul(aSaturateDbl(AVec3_dot(light, i->nor), 0.1, 1.0), s.col);
}
void Plane_intersect(Object p, AVec3 rayOrigin, AVec3 rayDir, AVec3 light, Isect *i)
{
double d = - AVec3_dot(p.pos, p.nor), v = AVec3_dot(rayDir, p.nor);
if (v * v < 1.0e-30) return;
double t = - (AVec3_dot(rayOrigin, p.nor) + d) / v;
if (t < 1.0e-4 || t > i->distance) return;
AVec3 hp = i->hitPoint = AVec3_add(rayOrigin, AVec3_mul(t, rayDir));
i->distance = t; i->nor = p.nor;
double d2 = aSaturateDbl(AVec3_dot(light, i->nor), 0.1, 1.0);
if ((aReminder1(hp.x, 2) - 1) * (aReminder1(hp.z, 2) - 1) > 0) { d2 = d2 / 2; }
i->col = AVec3_mul(d2 * (1.0 - aSaturateDbl(fabs(hp.z) * 0.04, 0.0, 1.0)), p.col);
}
void Util_intersect(Util u, AVec3 rayOrigin, AVec3 rayDir, Isect *i)
{
i->distance = 1.0e+30;
Sphere_intersect(u.s1, rayOrigin, rayDir, u.light, i);
Sphere_intersect(u.s2, rayOrigin, rayDir, u.light, i);
Sphere_intersect(u.s3, rayOrigin, rayDir, u.light, i);
Plane_intersect (u.p, rayOrigin, rayDir, u.light, i);
}
void aMain(AComArg *aCA)
{
Util u; Isect i; AInt16 ix, iy, j;
u.s1.rad = 0.5; u.s1.pos = AVec3_new( 0.0, -0.5, 0.0); u.s1.col = AVec3_new(1, 0, 0);
u.s2.rad = 1.0; u.s2.pos = AVec3_new( 2.0, 0.0, cos(6.66)); u.s2.col = AVec3_new(0, 1, 0);
u.s3.rad = 1.5; u.s3.pos = AVec3_new(-2.0, 0.5, cos(3.33)); u.s3.col = AVec3_new(0, 0, 1);
u.p.nor = AVec3_new(0, 1, 0); u.p.pos = AVec3_new(0, -1, 0); u.p. col = AVec3_new(1, 1, 1);
AWin *win = aOpenWin(512, 384, "kray"); u.light = AVec3_new(0.577, 0.577, 0.577);
for (iy = 0; iy < 384; iy++) {
for (ix = 0; ix < 512; ix++) {
AVec3 rayDir = AVec3_normalize(AVec3_new(ix / 256.0 - 1, (384 - iy) / 256.0 - 1, -1));
Util_intersect(u, AVec3_new(0.0, 2.0, 6.0), rayDir, &i);
AVec3 dstCol = AVec3_mul(rayDir.y, AVec3_new(1, 1, 1));
if (i.distance < 1.0e+30) {
AVec3 tmpCol = dstCol = i.col;
for (j = 1; j < 4; j++) {
rayDir = AVec3_add(rayDir, AVec3_mul(-2.0 * AVec3_dot(rayDir, i.nor), i.nor));
Util_intersect(u, i.hitPoint, rayDir, &i);
if (i.distance >= 1.0e+30) break;
tmpCol = AVec3_new(tmpCol.x * i.col.x, tmpCol.y * i.col.y, tmpCol.z * i.col.z);
dstCol = AVec3_add(dstCol, tmpCol);
}
}
aSetPix(win, ix, iy, aRgb8(col256(dstCol.x), col256(dstCol.y), col256(dstCol.z)));
}
}
aWait(-1);
}
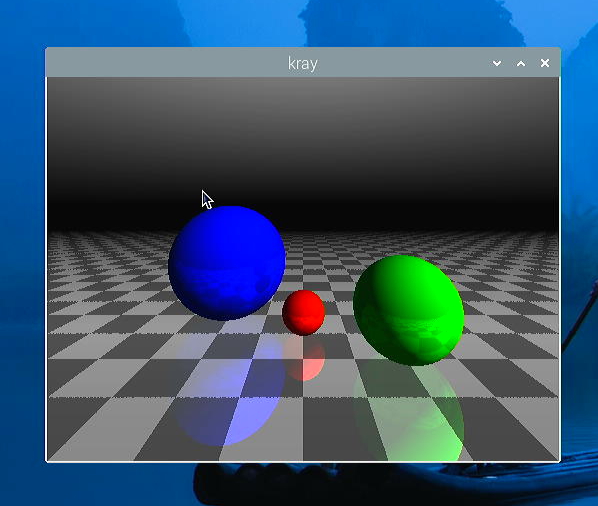
- レイトレーシングの演算が想像していたよりも速く感じたので、mandel.cも実行してみました。私にとっての定番のベンチマークです。
#include <acl1.c>
void aMain(AComArg *aCA)
{
AWin *w = aOpenWin(512, 384, "mandel");
int x, y;
for (y = 0; y < 384; y++) {
for (x = 0; x < 512; x++) {
int sn = 0, sx, sy, n;
AInt c, cx, cy, zx, zy, xx, yy;
for (sx = 0; sx < 4; sx++) {
cx = (x * 4 + sx) * 56 + 4673536;
for (sy = 0; sy < 4; sy++) {
cy = (y * 4 + sy) * (-56) - 124928;
zx = cx; zy = cy;
for (n = 1; n < 447; n++) {
xx = aMul64Shr(zx, zx, 24);
yy = aMul64Shr(zy, zy, 24);
if (xx + yy > 0x4000000) break;
zy = aMul64Shr(zy, zx, 23);
zx = xx + cx - yy;
zy = zy + cy;
}
sn = sn + n;
}
}
n = sn >> 4;
c = aRgb8(n, 0, 0);
if (n >= 256) {
c = aRgb8(0, 0, 0);
if (n < 447) {
c = aRgb8(255, n - 255, 0);
}
}
aSetPix(w, x, y, c);
}
}
aPrintTime();
aWait(-1);
}
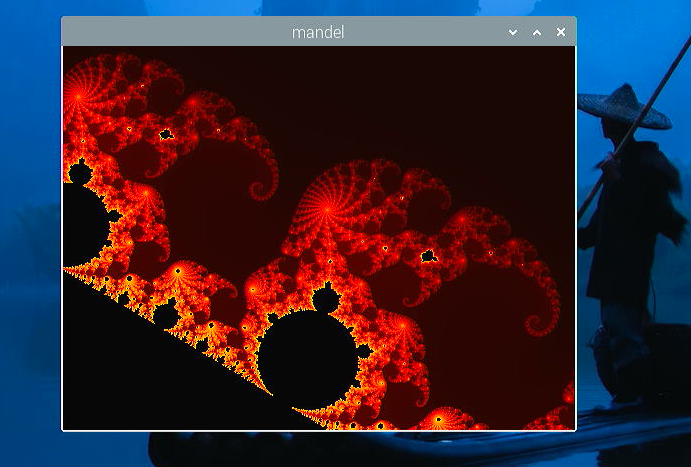
- 肝心の演算時間は6.1秒でした(AIntをAInt32にすると少し速くなります)。
- やるなー、結構速いじゃんって思ったのですが、手持ちの安いPCで実行すると、x86で2.8秒、x64なら2.3秒でした。・・・あれ、6.1秒は全然速くなかった・・・。
2024.05.09(木) #3
- コンパイルオプション
RasPiZero2W: gcc -I../acl1 -DAOs_Linux -DAGraph_X11 -DAArch_AArch64 -O3 mandel.c -Wl,-s,-dy -lm -lX11
Win_x86: cl /O1 /MD /W3 /Fm:mandel.map /Zo- /D_CRT_SECURE_NO_WARNINGS /DAArch_X86 /DAGraph_Win /I..\acl1 mandel.c /link kernel32.lib gdi32.lib User32.lib Winmm.lib
Win_x64: cl /O1 /MD /W3 /Fm:mandel.map /Zo- /D_CRT_SECURE_NO_WARNINGS /DAArch_X64 /DAGraph_Win /I..\acl1 mandel.c /link kernel32.lib gdi32.lib User32.lib Winmm.lib
- 実行ファイルの大きさ(バイト)
| mandel | kcube | kray |
| RasPiZero2W | 67808 | 67800 | 67808 |
| Win x86 | 11776 | 14848 | 16384 |
| Win x64 | 14336 | 16896 | 18432 |
- うーん、Zero2Wだと実行ファイルサイズを小さくするのはあまり得意ではなさそう。残念。
2024.05.10(金) #1
- Zero2Wは本当にすごいです。そりゃあもちろん2~3万円程度のノートPCと比べたらメモリは少ないしスピードも遅いけど、でも3千円程度ですよ。それでここまで遊べるってすごいですよ!
- mandelだって2.6倍くらいしか遅くないわけです。これは許容範囲ですよ!
こめんと欄
![[PukiWiki]](image/pukiwiki.png "[PukiWiki]")